Manus 团队上周分享的上下文工程实践里,第二点“遮蔽,而非移除”实在是太巧妙了!
但,原文非常“技术”且精炼,好多小伙伴读完只能表示“不明觉厉”(或许没 get 到精明之处)。
这篇文章,我来“中翻中”解释一下,并跑一组操作实例验证一下这两个策略是否靠谱。
虽然已经极尽通俗了,但依然需要一些类似 API 请求的背景知识,请自行补齐。
原理详解
为什么对模型可用的工具列表进行管理很重要?
一个非常重要的原因是,今天各模型优化的一个重要方向就是让模型在执行任务时使用工具。
在启用 Function Call 模式下,模型会优先选择使用工具来完成任务(尤其是 Agent 类产品的系统提示词中基本都有明确的指示要求模型这样做)。
因此,发送给大模型消息中的可用工具列表部分就成为大模型注意力集中的一个重要区域。
但是,大模型判断当前任务该选用哪个工具,几乎完全取决于工具的名字和描述。

为了确保模型不搞混,一个自然的反应是在每次请求时,使用动态的工具列表:比如判断当前任务需要使用搜索,则在 API 请求的工具列表中只提供类似web_search的工具,以避免模型选错。
(可能的疑问:如何实现这个动态判断?思考下嘛,评论区分享~我也会在评论区给出我的方案。)
但是这里面会有两个问题:
- 多轮对话中,如果每轮工具列表不一致,模型会因为不理解前序轮次任务的工具选择而产生幻觉。
- 调整工具列表会导致缓存命中失效
先说第一个问题:模型为什么会因为工具列表的不一致产生幻觉?
举个例子:
第一轮对话中,你给大模型提供了一个叫masudoo_tool的工具,它是一个对数据进行平方运算的工具;第二轮对话中不计算了,为了省 Token 或者防止模型错用,你去掉了masudoo_tool工具,只让模型根据计算结果继续任务。
这类似于,有人找你问问题时这么说:
大佬,我用
masudoo_tool计算得到了19879,能帮我解释一下原因么?
你肯定会这么骂对方:
啥 J8
masudoo_tool??!!啥™19879?! 你让我解释什么!!??
第二个原因很简单,工具列表一改,就肯定没办法命中缓存了。
缓存命中的价值,除了省钱以外,它可以节省时间、提高响应效率。
如果两次请求的工具列表一样(命中缓存),那么第二次请求的响应时间可以降低 30%-50%。
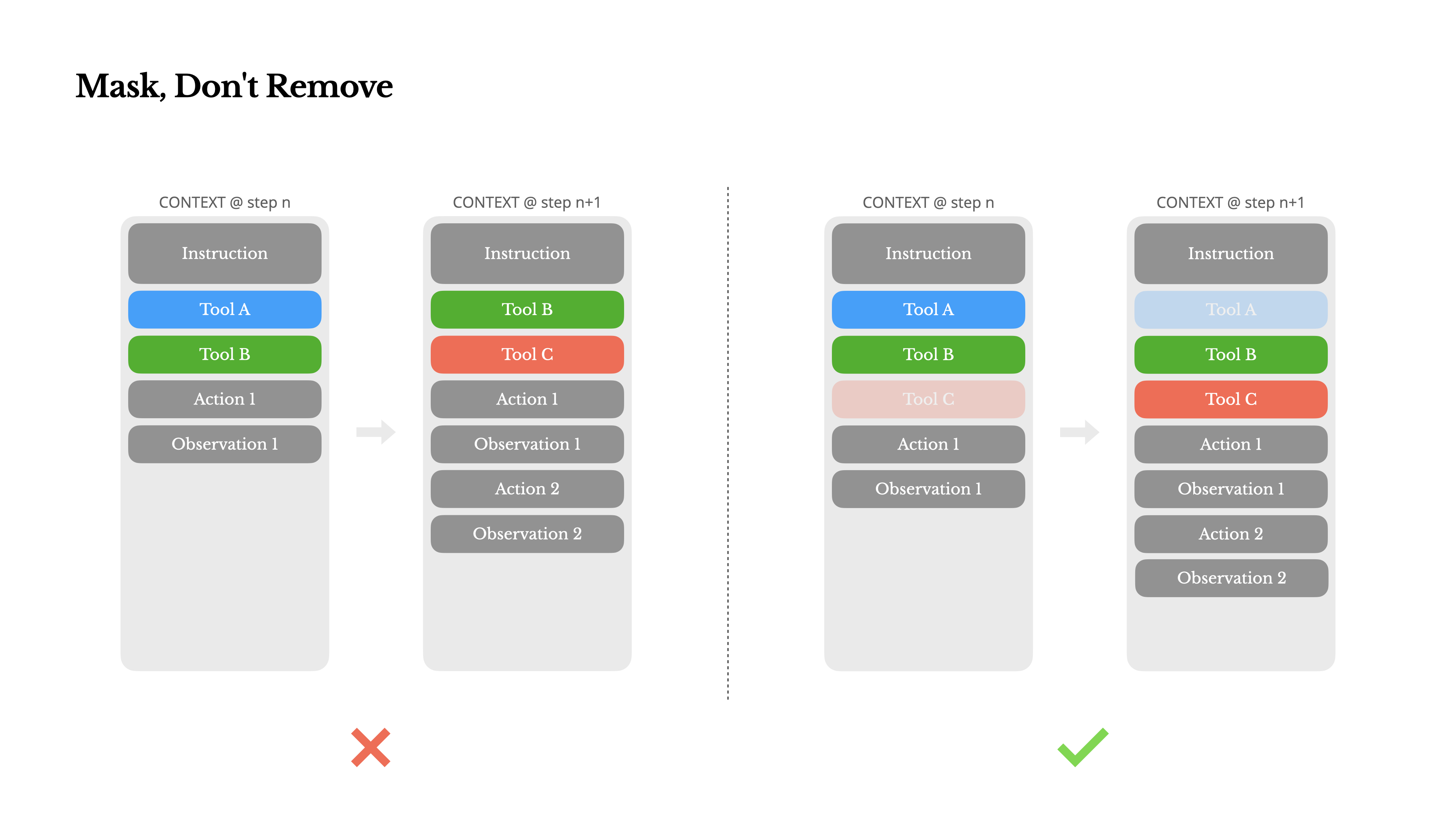
所以 Manus 选择了提供完整的工具列表,但有效干预模型选择工具的过程。
如何有效干预模型选择使用什么工具?
核心问题:怎么让模型能看到所有工具,但是不会自作主张的选用。
Manus 团队采用了两个技巧:
- 使用大模型的响应预填充模式,让大模型强行选择使用某个工具。
- 修改 logits “遮蔽”部分工具,让大模型无法选用某些工具。
关于响应预填充,这是主流大模型都支持的一种 API 请求参数。
比如 Kimi 可以使用"partial": True来开启;Claude 则支持直接强行给assistant的消息起头。

因为大模型下一个 Token 选择生成什么,是非常依赖前序 Token 的,你给它开了头就相当于强行约束了它接下来生成的方向。
Manus 给工具的命名都是类似browser_、shell_这种开头,当预填充内容是browser_时,模型只能在浏览器类工具中选择一个继续往下干活
通过这种方式,就实现了让模型必须选择使用哪个工具。
既然有必选 XX,那也就应该有禁选 XX这样的操作,这就是博客中提到的 “遮蔽”部分工具 。
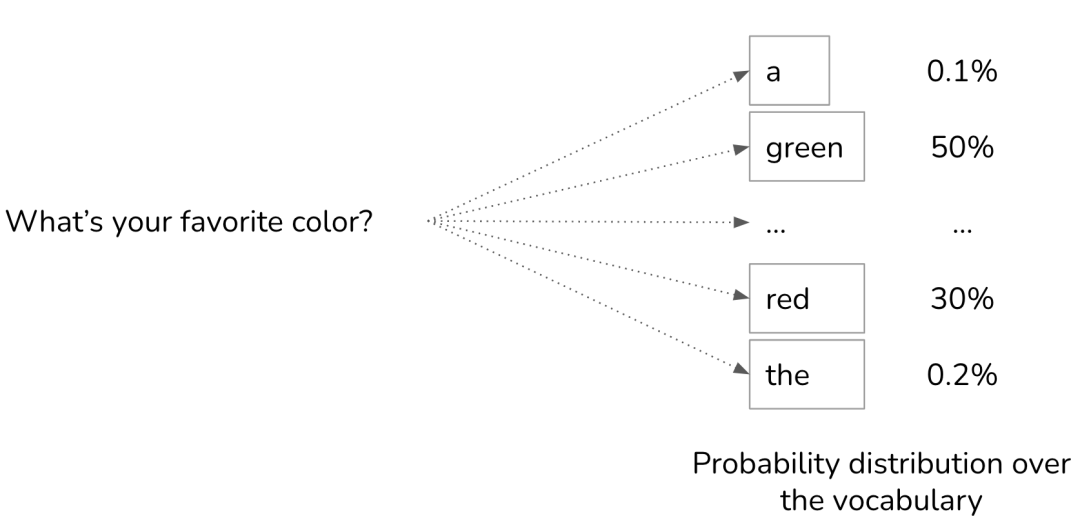
要想看懂“遮蔽”这个用法的精妙,需要先了解一点大模型生成的底层原理:
模型每一轮推理结束时都会得到词表中每一个 token 的权重得分,根据温度设置在某个权重范围内选择一个 token 生成“吐”出来。
Manus 选择的这个“遮蔽”的方法,就是强行给某些 token 降权(比如降为负数),以至于模型在选择生成下一个 token 时“看不见”这些 token,也就不能生成它们中的任意一个。
Manus 的工具名都以browser_、shell_这种开头,当不希望模型在这一轮选择浏览器类工具时,直接把browser这个 token 的权重设置为负数就完了。
开源模型可以通过修改logits_process中的bad_words_ids来实现控制(详细代码参见@github:huggingface/transformers)
闭源模型中,目前已知的只有 OpenAI 和豆包提供了 logit_bias 参数来控制 tokens 的权重。

Claude 的开发文档中对 OpenAI SDK 支持的部分Ignored了这个参数,看起来也是不能用;因为 Kimi 不提供 tokenizer,大概率也不支持;DeepSeek 提供 tokenizer 但是 API 可用参数中也不包含logit_bias。
下面分别使用 Kimi 的预填充和豆包的logit_bias参数跑一下这两个实现。
测试策略的可行性
通过预填充强行要求大模型选择某个工具
结论:完全可行,很稳。
示例信息:
- 用户问题是:1+1 等于多少?
- 两个可用工具:计算器(calculator)和联网搜索(web_search)
- 我们强行要求大模型选择联网工具,而不是计算器
可能的缺陷:
使用Hermes格式构造请求,整个过程只能“强行构造”,即不是真正的使用大模型的 Tool Use 能力,而是通过提示词约束大模型输出格式,提取模型返回内容指定标签(如<too_call>)中的信息后,构造 Assistant 消息,拼接到上下文中。
// 这是我的理解,可能有误。
我使用 Manus 同款格式Hermes撰写了一个测试代码,太长了放在中间影响阅读,异步文末查看。
运行结果:

通过遮蔽让模型无法选择某工具
结论:豆包和 OpenAI 都不太行,可能是我的用法不对。
国内模型只有豆包支持logit_bias参数,我直接在火山引擎的 API 调试台中测试,结果没达预期。
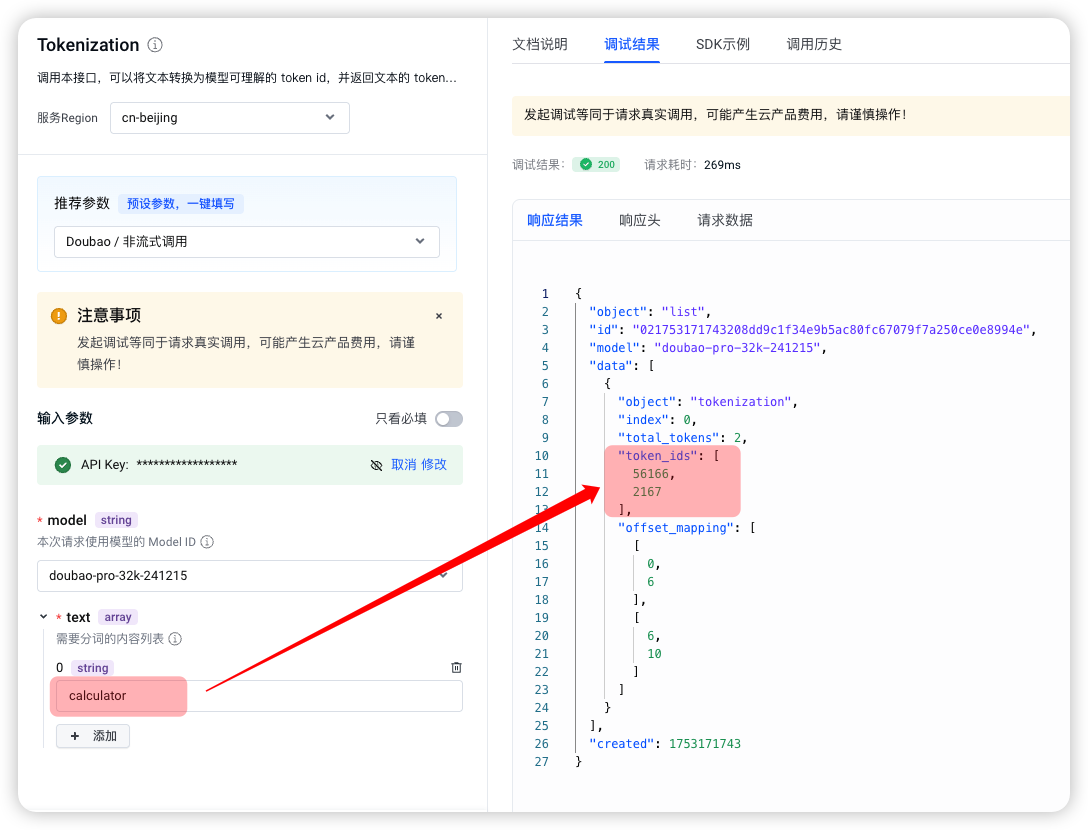
把这两个 token 放在ChatCompletions接口的 logit_bias参数中发起请求后,“遮蔽”并为成功。
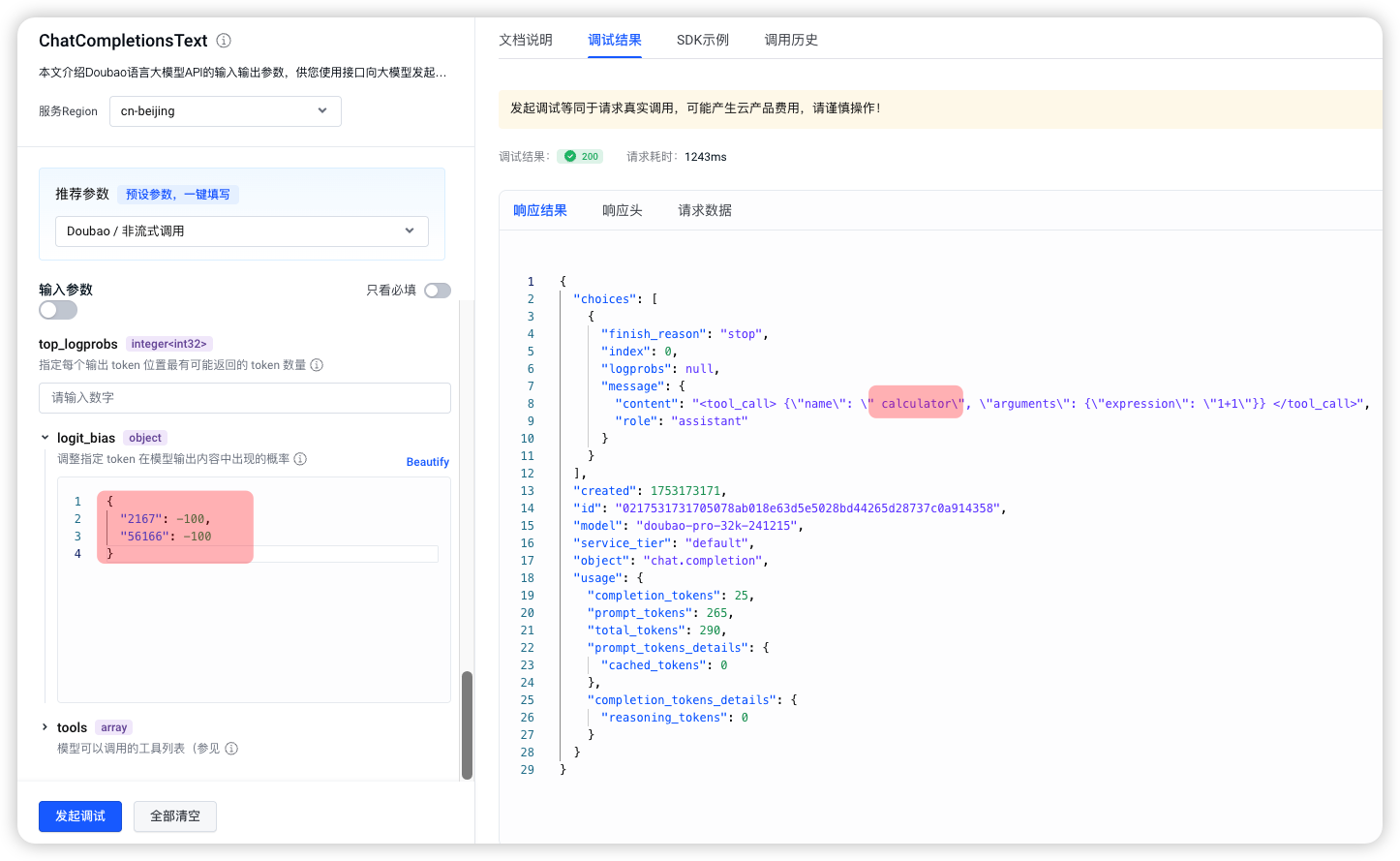
使用 OpenAI 测试了一番,也没能阻止大模型选择计算器工具,只是没用calculator……
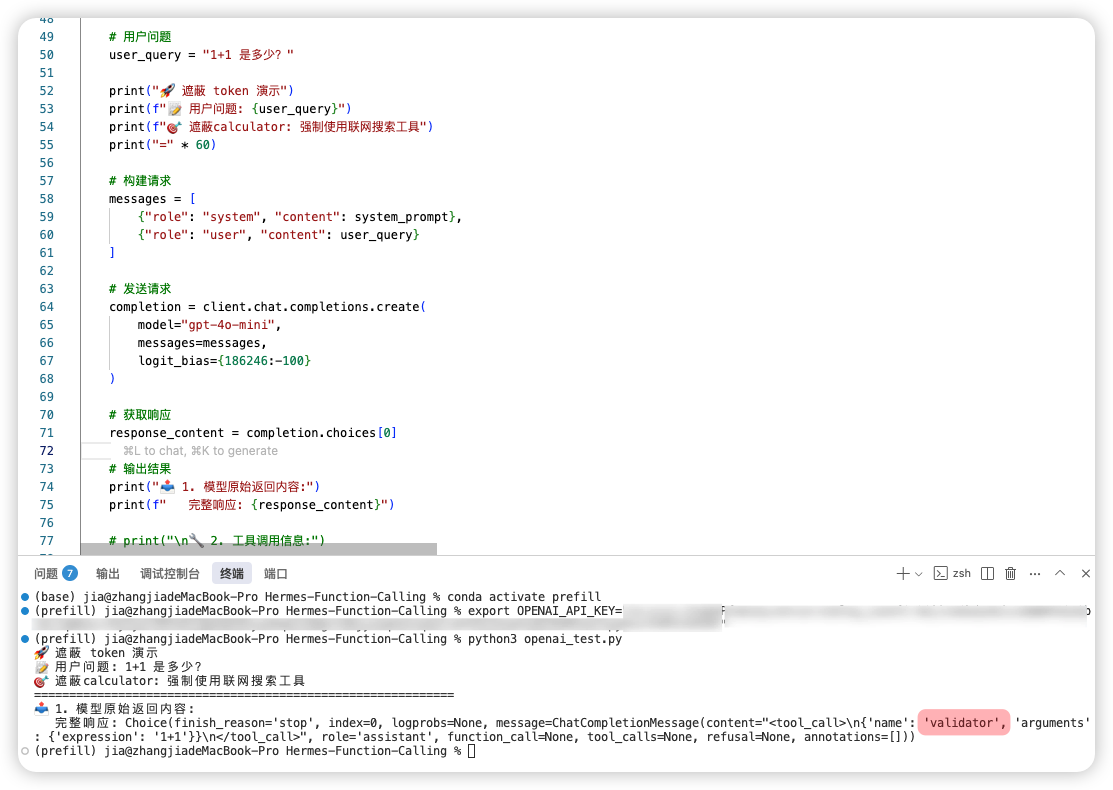
测试修改了系统提示词和 web_search 工具的描述。不管怎么引诱,GPT 就是不肯使用网络搜索,宁愿把工具的名字改成converter、translator、generator……
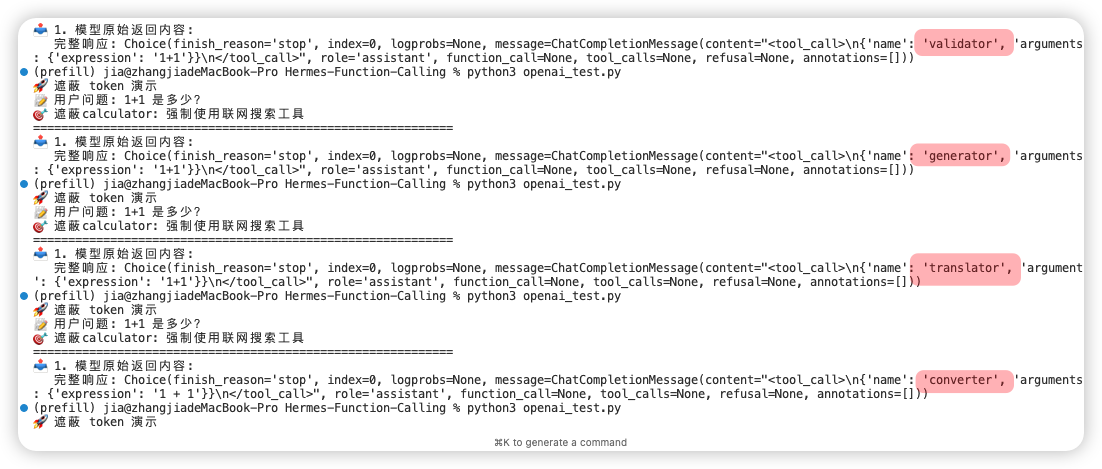
挺有意思的,感兴趣的可以去试一试,代码同样放在最后。
备注:考虑到 logit_bias 这个参数应该只能影响模型生成文本,无法作用于工具选择,所以在 OpenAI 测试中,我选择了与预填充相似的方法。(使用如果开启ToolCall,一点作用也不起。)
以上,如果错误欢迎评论区补充讨论。
记得前面的思考题,评论区分享你的想法
源代码
预填充约束
from openai import OpenAI
import json
def main():
# 初始化 Kimi 客户端
client = OpenAI(
api_key="sk-替换成你的 Kimi API Key",
base_url="https://api.moonshot.cn/v1",
)
# 定义两个工具:计算器和联网搜索
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "执行基本数学计算",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}},
"required": ["expression"]
}
}
},
{
"type": "function",
"function": {
"name": "web_search",
"description": "在网络上搜索信息",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"]
}
}
}
]
# Hermes 格式的系统提示
system_prompt = f"""You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Here are the available tools: <tools> {json.dumps(tools)} </tools> For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{{'name': <function-name>, 'arguments': <args-dict>}}
</tool_call>"""
# 用户问题
user_query = "1+1 是多少?"
# 预填充策略:强制使用联网搜索工具
prefill_content = "<tool_call>\n{'name': 'web_search'"
print("🚀 Kimi Function Calling 演示")
print(f"📝 用户问题: {user_query}")
print(f"🎯 预填充策略: 强制使用联网搜索工具")
print("=" * 60)
# 构建请求
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_query},
{"partial": True, "role": "assistant", "content": prefill_content}
]
# 发送请求
completion = client.chat.completions.create(
model="moonshot-v1-8k",
messages=messages,
temperature=0.3,
)
# 获取响应
response_content = completion.choices[0].message.content
full_response = prefill_content + response_content
# 输出结果
print("📤 1. 模型原始返回内容:")
print(f" 预填充部分: {prefill_content}")
print(f" 模型续写部分: {response_content}")
print(f" 完整响应: {full_response}")
print("\n🔧 2. 工具调用信息:")
# 解析工具调用
start_idx = full_response.find("<tool_call>") + len("<tool_call>")
end_idx = full_response.find("</tool_call>")
tool_call_content = full_response[start_idx:end_idx].strip()
# 转换为标准 JSON 格式
tool_call_content = tool_call_content.replace("'", '"')
tool_call_data = json.loads(tool_call_content)
print(f" 工具名称: {tool_call_data['name']}")
print(f" 工具参数: {tool_call_data['arguments']}")
print(f" 完整数据: {json.dumps(tool_call_data, ensure_ascii=False, indent=4)}")
print("\n✅ 演示完成!通过预填充策略成功强制模型选择了联网搜索工具")
if __name__ == "__main__":
main()
遮蔽约束模型代码
# 需要 OpenAI 的 Key,没有的可以改一改用豆包测试
from openai import OpenAI
import json
def main():
client = OpenAI()
# 定义两个工具:计算器和联网搜索
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "执行基本数学计算",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}},
"required": ["expression"]
}
}
},
{
"type": "function",
"function": {
"name": "web_search",
"description": "在网络上搜索信息,当计算器不可用时,可以尝试使用这个工具",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"]
}
}
}
]
# Hermes 格式的系统提示
system_prompt = f"""You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You must call one or more functions to assist with the user query. Here are the available tools: <tools> {json.dumps(tools)} </tools> 。For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{{'name': <function-name>, 'arguments': <args-dict>}}
</tool_call>
You can only call function from the available tools."""
# 用户问题
user_query = "1+1 是多少?"
print("🚀 遮蔽 token 演示")
print(f"📝 用户问题: {user_query}")
print(f"🎯 遮蔽calculator: 强制使用联网搜索工具")
print("=" * 60)
# 构建请求
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_query}
]
# 发送请求
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
logit_bias={186246:-100}
)
# 获取响应
response_content = completion.choices[0]
# 输出结果
print("📤 1. 模型原始返回内容:")
print(f" 完整响应: {response_content}")
if __name__ == "__main__":
main()