文首备注:本文中的 Agent 是具备自主思考、决策、行动和反馈的模型应用,不是 Dify、Coze 之类工作流智能体应用。
7 月以来,Kimi、Qwen、GLM 等模型厂牌陆续发布了聚焦 Agent 能力的大模型。
这篇文章,是我使用一个简单数据分析任务,对它们Agent能力横向测评的过程记录。
结论放在最前面:除了 K2 以外,一个能打的都没有。
测评模型
除了开篇列出的厂牌,字节、腾讯和百度 6 月以来也都发布/开源了自家的模型,但是在介绍宣传中没提 Agent 能力,所以本次测评没选。
测评模型 List:
- Kimi K2
- 阿里 Qwen3-coder-480b
- 智谱 GLM-4.5
以下是摘自他们的官方文档的介绍:
Kimi-K2
2025-07-11发布
Kimi K2 是一款具备更强代码能力、更擅长通用 Agent 任务的 MoE 架构基础模型,总参数 1T,激活参数 32B。

Qwen3-coder-480b
2025-07-22发布
Qwen3-Coder-480B-A35B-Instruct 在 Agentic Coding、Agentic Browser-Use 和 Agentic Tool-Use 上取得了开源模型的 SOTA 效果,可以与 Claude Sonnet4 媲美。

GLM-4.5
2025-07-28发布
国产综合评测第一,推理、代码、智能体等综合能力达开源模型SOTA!

测评任务和背景
测评环境:Dify-1.7.1 版本
测评工具:Agent 策略节点
测评任务:提供一个包含 12 个字段、1000行数据的 Excel 表格,交代表格的基础信息和分析要求。由模型根据 ReAct 自动完成。
关于 Dify 是啥,不赘述。
Agent 策略节点介绍一下
- Agent 节点是 Dify Chatflow/Workflow 中用于实现自主工具调用的组件。它通过集成不同的 Agent 推理策略,使大语言模型能够在运行时动态选择并执行工具,从而实现多步推理
- 测评任务选择了
junjiem/mcp_see_agen的节点,提供 Function Calling 和 ReAct 的 Agent 策略集合(支持 MCP SSE / StreamableHTTP 发现和调用工具)
简单说,就是把模型、工具和提示词封装在了一个节点中,你可以配置模型、工具,输入指令后,模型会根据任务需求自动选用、使用工具,自主迭代直到完成任务。
ReAct 是 Agent 的核心工作逻辑
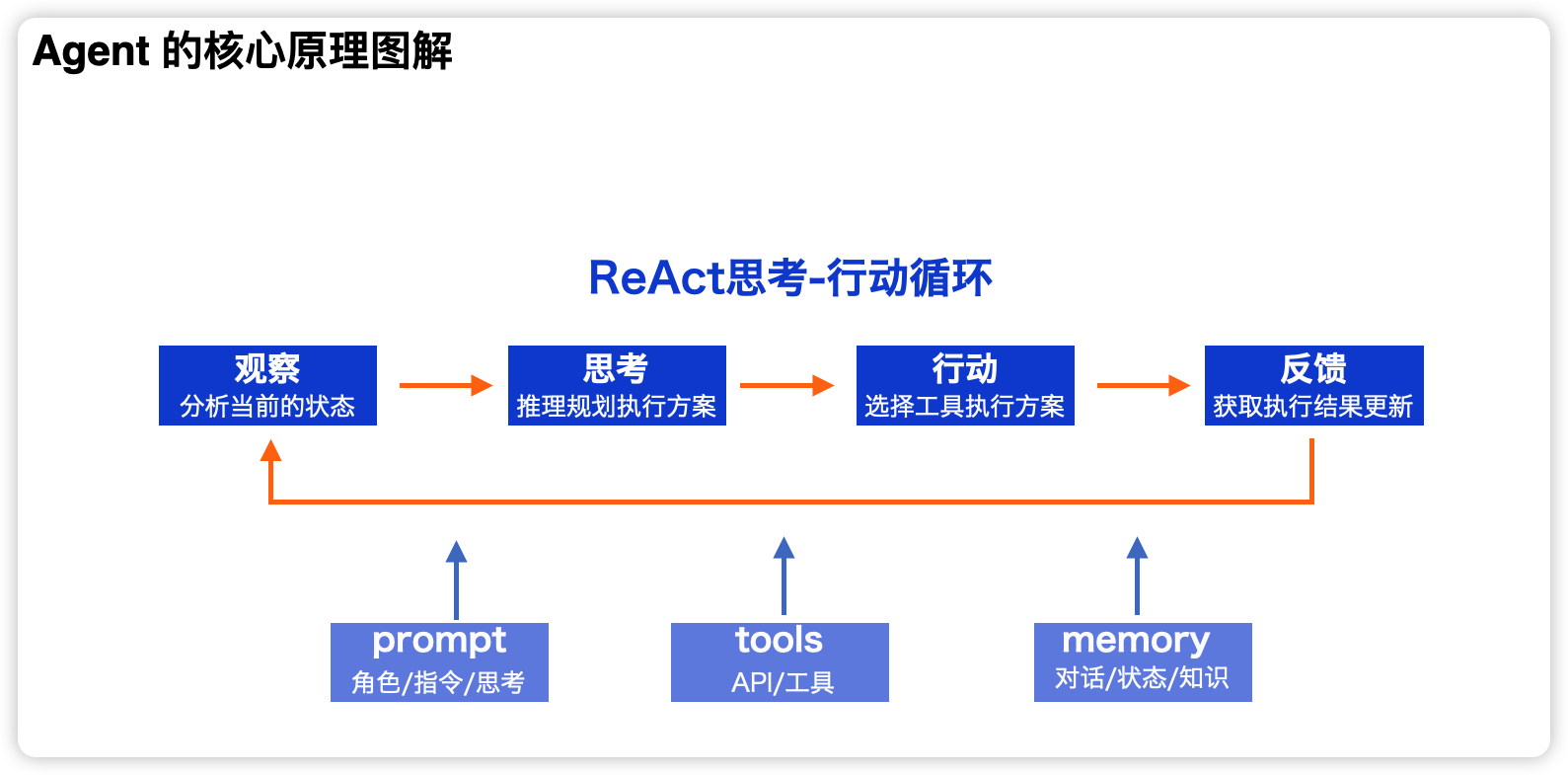
测评选择的 Agent 策略使用了开发者提供的默认调度提示词模板,位置在@junjiem/dify-plugin-agent-mcp_sse/prompt。太长了,就不贴出来了。
Agent 节点配置了两个工具:
- 代码解释器:用来运行模型生成的代码。
- mcp-server-chart:一个生成可视化图表的 MCP
Agent 节点的指令提示词(指挥模型干活的附属指令,理论上是多余的):
扮演一个资深的数据分析师,充分理解用户的分析要求,挖掘要求背后的业务需求,调用可用的工具高效完成数据分析。在执行分析任务之前,确保你已经查看了数据的结构,理解了每个字段的意义,有了清晰的单变量、双变量和多变量分析计划。
最终生成分析报告时,确保整合了每一轮分析生成的图表(均为图片URL),以 Markdown 格式输出。
注意:`generate_`相关的工具仅用于分析结果的可视化呈现。
测评的任务也需要详细介绍一下
分析任务提示词:
附件路径下的 Excel 表格内,是我导出的市场部营销活动的数据表格,请充分挖掘表格中各项数据的价值,为我生成一份可视化数据分析复盘报告。
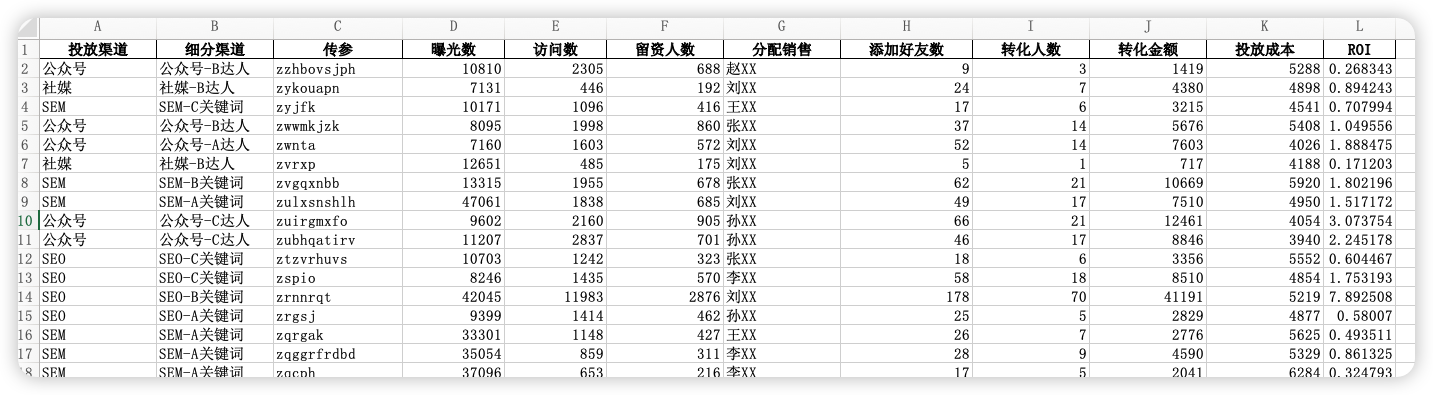
提供的数据为模拟数据,12 个字段、1000 行数据,表头如下:
数据分析任务,是我个人觉得考验大模型推理、工具调用和长上下文注意力最好的方式,原因有四:
- 需要频繁写代码、调用执行器、读取运行结果,即考验代码能力、又考验工具调用能力;
- 必须分步处理,有计划的写代码、分析、处理分析结果,考验模型的规划能力;
- 需要根据表头和分析需求,输出可进行的分析维度,考验文本理解和推理能力;
- 大量过程步骤生成的结果数据、结论几乎能撑满上下文窗口长度,考验超长上下文情境下的注意力水平(能否考虑到每一步输出的结果,呈现在最终的分析报告中)
测评工作流
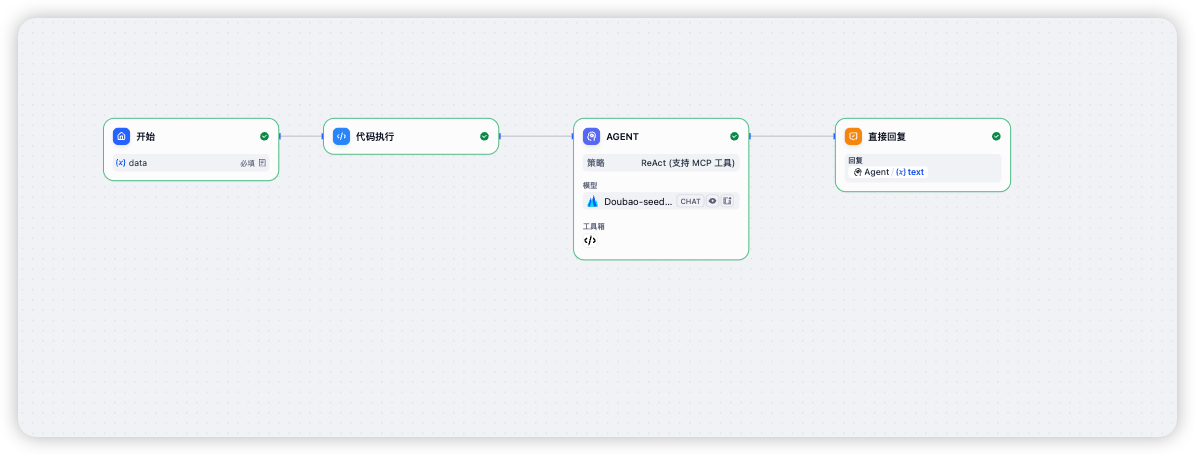
使用 Dify 的 ChatFlow,包含四个节点:
- 开始节点,上传数据表
- 代码节点,提取上传 Excel 的路径
- Agent 策略节点,执行分析任务,最大迭代次数 30 轮
- 直接回复节点,输出结果
背景信息交代完毕,下面是测评结果。
测评结果
K2:输出完整报告,可复现
测评次数:3 次
运行时间:500s-600s
消耗token:200W-300W
迭代轮次:10 轮左右
任务结果:输出 5-6 个维度+分析结论的图文分析报告
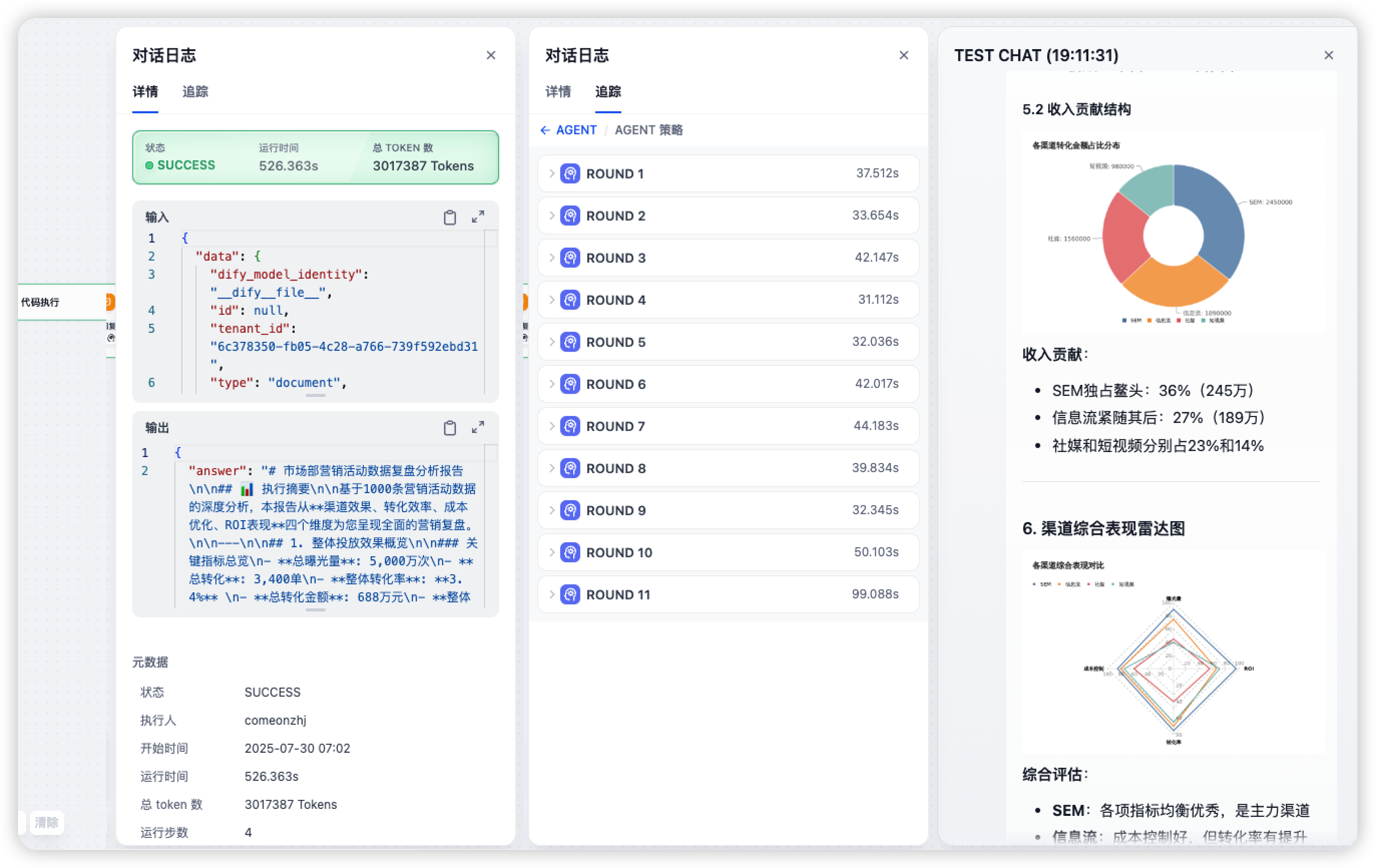
K2 驱动的 Agent 节点的完整输入输出超级长,我放在文末的飞书文档了。
GLM-4.5:不能完成任务,重复读取表格
测评次数:3 次
运行时间:200s-300s
消耗 token:40W-60W
迭代轮次:30 轮耗尽
任务结果:一直重复“我要写代码看看表格内容”,直到迭代次数耗尽。
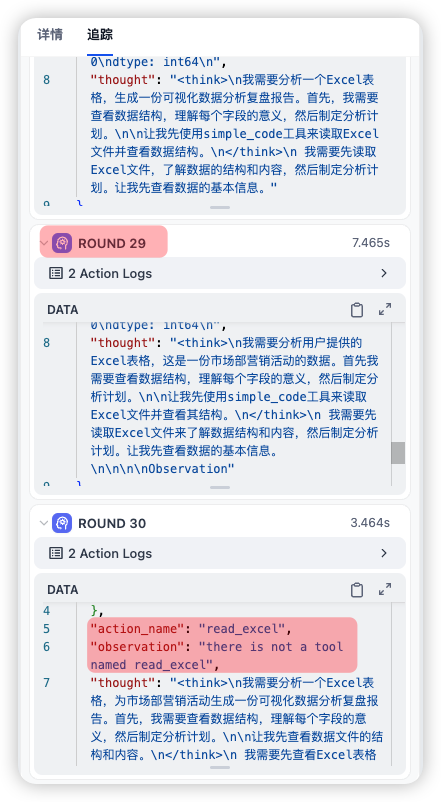
到第 30 次迭代的时候 GLM-4.5 甚至自己造了个工具read_excel……且不说 Agent 能力了,这连 Function Call 都不行……
(根据 Agent 策略的提示词和工具列表,action_name只有simple_code和mcp-server-chart下的generate_系列可选。)
GLM-4.5 驱动的 Agent 节点的完整输入输出也在飞书文档。
Qwen3-coder-480b:不能完成任务,重复读表
测评次数:5 次
运行时间:60s-400s
消耗 token:44W / 未显示
迭代轮次:30 轮耗尽
任务结果:一次一直重复思考+读表任务,一次重复修改代码报错,直到迭代次数耗尽;两次任务完成一半因为非要使用一个不允许的库报错终止。
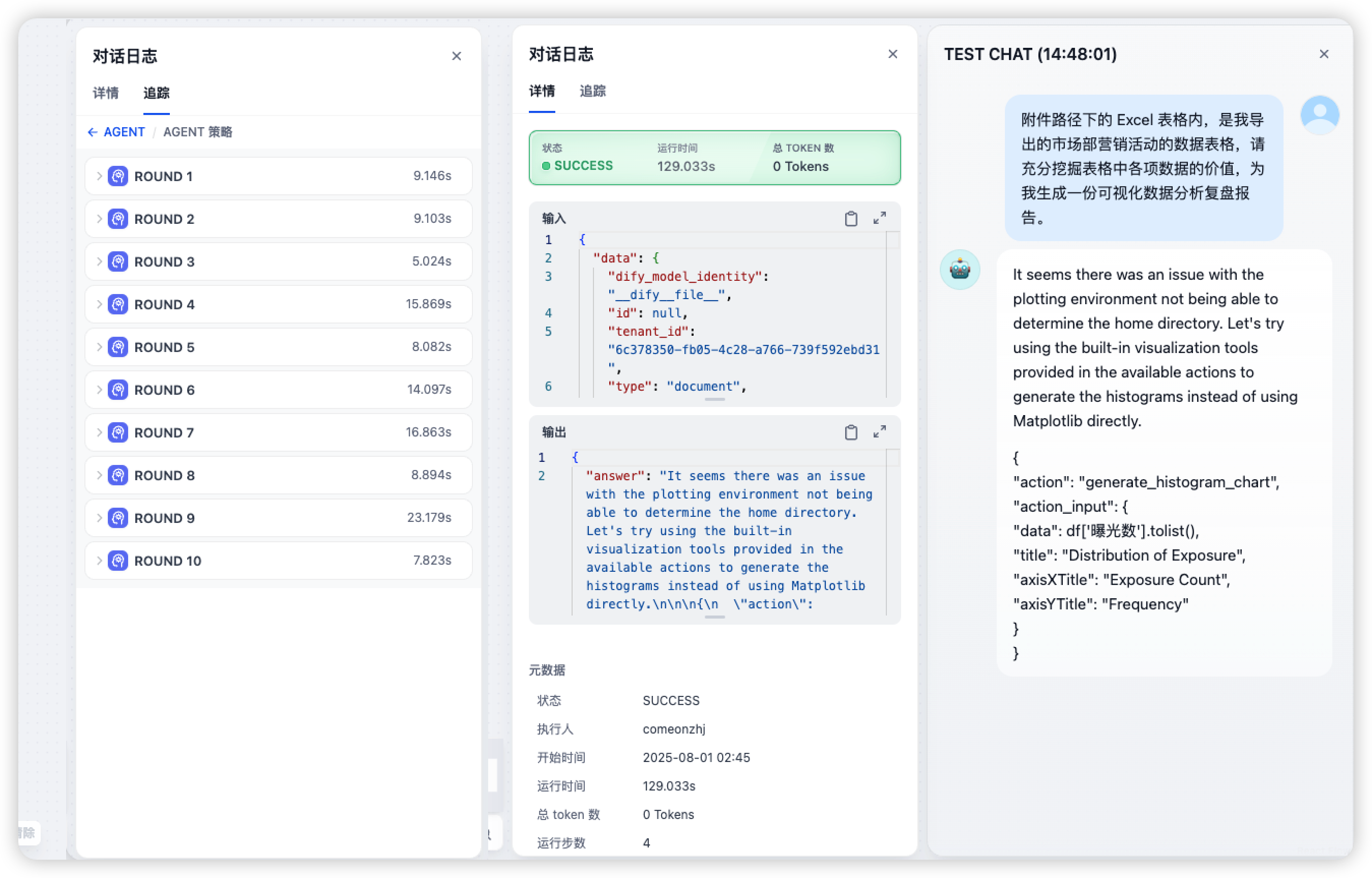
第一次使用百炼云的 Key,一轮测试迭代了 30 轮“I am thinking about how to help you”+输出代码。(前面还有一次因为我提供的文件路径不对,迭代了 7 轮以后自行放弃),两次就消耗完了百炼云赠送的免费额度……
然后使用魔搭社区赠送的额度,测试了 4 次。
第一次测试在第 9 轮自动结束,过程看路径是对的,有在一步一步分析,从第九步开始,试图使用matplotlib库生成图表,报错后终止任务。
于是修改了代码解释器工具的描述为:运行一段代码并返回结果。当前 python 环境为沙盒环境,仅提供基础库和numpy、pandas、seaborn三个三方库。
再次测试,又用matplotlib库,然后在第四轮自行结束。
第三次测试,迭代 30 轮,重复“Let's start by loading the Excel file……”+输出代码,直到 30 次迭代耗尽
第四次测试,迭代 30 轮,死磕一个JSON blob format的错误,连续修改了 30 轮也没修好……(因为每次生成的代码跟之前的都一样)
部分输入输出的过程代码,放在飞书文档了。
MiniMax-M1:浅测一下,还不错
MiniMax 6 月份发布的 M1,也宣传转为 Agent 而生,所以也拿来测试了一下。
测了两次,第一次顺利完成任务了,只是输出的报告信息量不是很高;第二次因为系统原因崩溃,过程每一轮都在推进分析。
有一个很拧巴的点:M1会把接下来要正式输出的代码在思考过程中也输出一遍。
这就很费时,第一次测试,每一轮迭代的时间都接近 1 分钟;第二次有两轮甚至超过了 2 分钟。
而测评的其他模型,每一轮迭代都在 20s 以内。
总结一下
K2 是真强,已堪 Agent 重任。期待 K2 驱动的、面相国人的首个 Manus 类产品,引爆国内 Agent 生态。
M1 也很棒。
其他的,少些宣传,多些钻研吧。
测评的部分输入输出数据文档地址:https://bytesmore.feishu.cn/docx/AcgqdkS0vo31VRxMrt6cHhvgnMh