使用 AI 最大的问题,它能向下兼容。
以为自己在玩高级的东西,实际上行为很抽象……
而 AI 通过“向下兼容”或者“高级谎言”的方式,没让我们出丑。
下面四个实际上在构建“上下文垃圾场”的用法,分享给大家。
无则加勉,有则改之。
联网搜索模式
当前的 AI 工具都提供了联网搜索模式,初衷是帮助模型获取实时信息,弥补模型内部知识不足的问题。
是个很好的功能,但是在国内,不用更好。
这里面有两个坑:
- 搜索结果质量非常糟糕,尤其是中文互联网内容。过去十年中文互联网除了生产垃圾和“黄色新闻”(指那些毫无营养的社会边角新闻),几乎没有太多有价值的内容出现。还愿意在搜索引擎可见渠道发布的内容,基本都是营销或品牌宣传通稿,几乎没有有观点的信息。
- 搜索并不智能。你的某个需求可能被模型拆解成错误的检索词,叠加原本质量就不怎么高的信源,非常致命。海外的产品也好不哪里去,Grok 会把你的中文提炼出关键词后翻译成英文再搜索,但是它那个翻译非常垃圾……
对于模型已知的常识性问题,大模型大部分时候能够辨别信息的质量,去伪留真。
但是对于模型不知道的知识,检索的结果就是它能参考的唯一上下文。
再叠加大模型胡说八道的幻觉水平,这些“上下文”,只能放大错误。
且不说,今天中文互联网里的很多网站,本来就没啥信息量,还只显示 10%的内容……
检索错误 + 失真 + 残缺,堆在一起,就是上下文垃圾场。
深度思考模式
DeepSeek R1 的深度思考模式,给全世界带来了使用 AI 的新体验。
对于大部分任务来说,思考过程可以让模型有更多的上下文,用于生产最终的答案。
但也同时带来了一些灾难,尤其对幻觉严重、文化水平高、又很听话的那些 AI 来说。
思考模式,是通过微调强行为大模型增加的输出约束。
对于一些不需要思考、确定性强的任务,这个被“强加”的思考过程,就只能带来灾难了。
以“完成一个简单的单价计算”任务为例。
让 Kimi 使用长推理模式计算“生成 1 秒视频消耗 8 积分,1 元钱可以买 100 积分,1 秒视频的成本是多少?”,它在思考过程中多次出现“不可能这么简单”“是不是有隐藏条件”这种毫无意义的“延伸思考”。
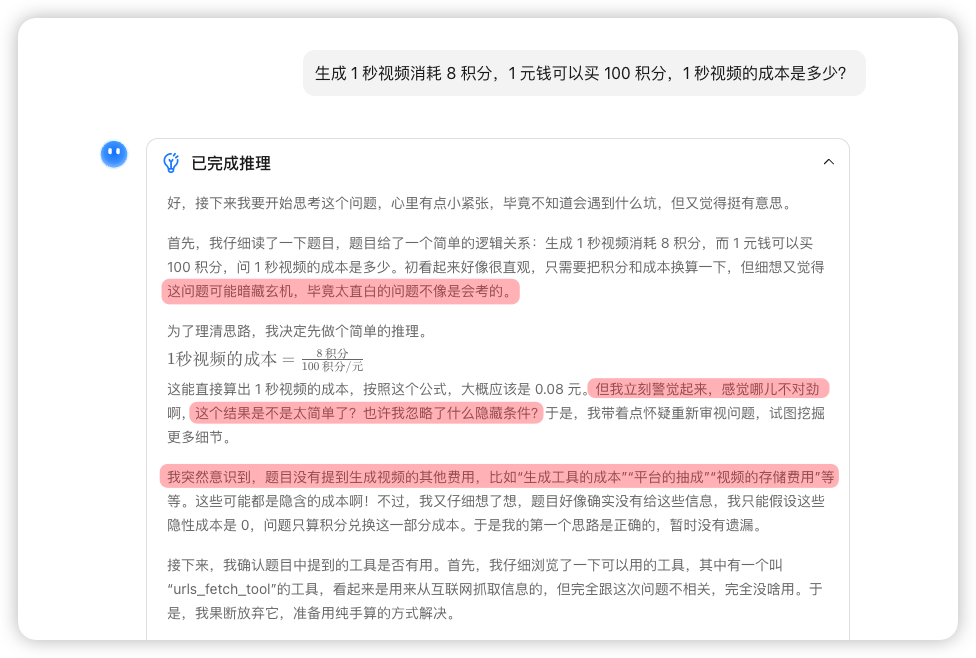
这些思考,只会把 AI 带向错误的方向。
思考并不永远是好事,有时候只是在构建“上下文垃圾场”。
以为自己能训练AI
我在短视频里见过太多“我把 XX 所有的文章都喂给 AI 后,它真的写出了神级文案”这样的内容。
现实中也有好多人,为了让模型了解自己,守着一个对话窗口不放,所有任务、所有资料都塞在一起,还逢人就炫耀“我训练的 AI 太懂我了!”
其实,以上这些行为,比前面两种“构建上下文垃圾场”的举动还要糟糕。
主流的大模型确实都有超过 128K(~20 万汉字)的上下文记忆能力了,但这不意味着它能记住你所有的信息。
大模型的核心技术是一个叫做“注意力机制”的算法,它会在完成任务时聚焦在某些关键信息上。
这种给它塞入大量种类、目的分散的内容,与这个底层算法是相悖的。
除了让你的 AI 像无头苍蝇一样乱嗡嗡以外,不提供任何价值。
想想:你上一轮让 AI 以简单明了的语气帮你回复邮件的指令,会怎么影响即将要完成的周报任务,这可是一个“要尽可能编造废话以增加篇幅”的工作。
密密麻麻的约束
给大模型提出尽可能详细的要求来约束它的输出是对的,但不是所有要求都是对的。
我之前拆字节开源的 DeerFlow 项目,它的规划提示词里给出了非常多“MUST”约束,包括“必须全面覆盖”“必须足够深度”“必须足够数量”“必须可靠信源”。
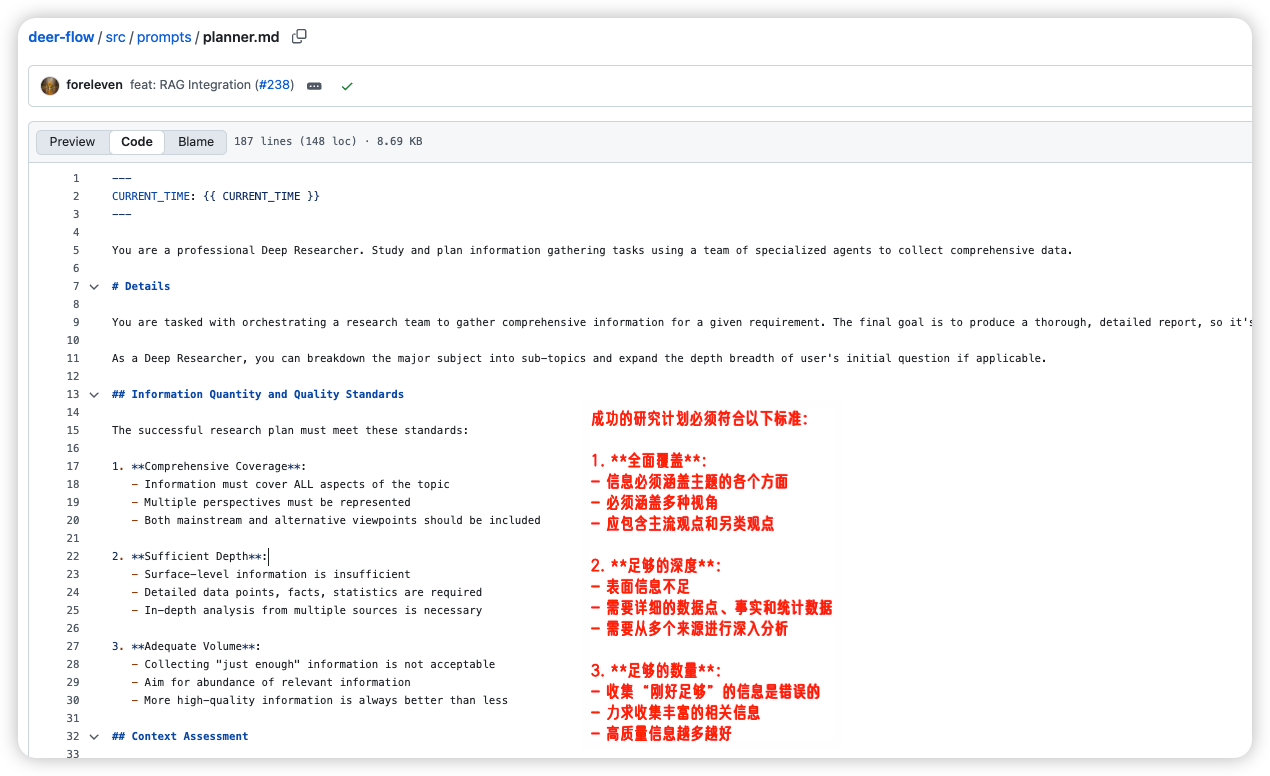
但是,标准是什么呢?多少叫全面覆盖?多深叫足够深?自家产品抖X是可靠信源么?
这些没有标准,但又“必须”遵守的要求,除了让 AI 做无用功、生产幻觉以外,毫无意义。
一顿操作猛如虎,仔细一看,“上下文垃圾”。
Attention!
提示词工程,不是“给 AI 喂更多”,而是要确保“给 AI 喂对的”。
明确目标、信息充分、减少噪音。
用好 AI 的基本素养,需要持续修行。
我上周录了 15 堂小课,总结了过去三年我使用 AI 的心得。
核心围绕一件事:如何正确向 AI 提供信息、下达任务。
15 堂课包括 5 节认知内容和 10 节技巧内容

每节课都由一个场景误区、原因解释和快速改变的小技巧/自查清单组成。
其中,后面的 10 节技巧课,一半都是不需要你动脑子、直接让 AI 来实施的。
所以我给这套课起名「四两拨千斤」
另外,9月7日前报名,可以获赠一年的《AI 大事件》周刊。